




2. 中国科学院 自动化研究所, 北京 100190
2. Institute of Automation, Chinese Academy of Sciences, Beijing 100190, P.R.China;
图像超分辨率技术应用在许多方面,如:数字高清晰度电视、遥感、医学影像分析公共安全等.目前各种场所安装了大量的监控系统.由于监控系统存在着成本制约、安装方式和监控系统现场拍摄距离的影响,使得从监控系统中获取的大量图像存在分辨率过低的问题.对这些低分辨率的图像进行分辨率增强在理论和实践中都是一个重要的课题.本文主要针对极低分辨率的人脸图像进行超分辨率重构.
从采样过程可以知道,低分辨率图像是由高分辨率图像经过模糊、变形、降采样和噪声污染得到的[1],整个降晰过程可以近似为一个线性过程.图像降晰模型可以表示为:

也可以简单表示为

其中Lo、Su、n分别表示低分辨率图像、高分辨率图像和噪声,DCF分别表示变形、模糊和降采样过程,H=DCF.在这里,假设低分辨率图像尺寸为 m×n,放大倍数为k,Lo、n为mm维列向量,Su为mnk2维列向量,H为mn×mnl2的矩阵.对超分辨率问题的求解,就是已知低分辨率图像Lo、降晰过程H、噪声分布n的情况下,利用上述表达式对Su进行估计.由H的维数可知,逆矩阵是不存在的,方程无法直接求解.
目前有如下几类典型的方法对上述问题求解:1、根据成像模型中降晰过程的作用来约束的方法,包括Tikohonov规整化方法[2]、Bayes重构方法[3,4]、基于集合论的投影到凸 集(POCS)方法[5]等.2、根据图像内像素的统计规律模型进行约束,包括小波域方法[6]、基于局部结构相似性方法①等.3、根据对特定类图像或结构进行学习从而引入有效约束,这类方法包括基于特征识别方法[7],②、神经网络学习方法[8]、基于流形学习的方法[9]、基于主分量学习的方法[10]等.本文算法的主要特点是利用人脸库以及人脸图像的相似性对超分辨率解空间进行约束:利用局部结构相似性将超分辨率解约束到人脸局部结构空间;将超分辨率解约束到人脸图像子空间,从而得到优化的超分辨率解.本文第1部分介绍了与本文密切相关的基于样本库学习和基于特征人脸的人脸图像放大方法,第2部分详细论述了基于样本库和特征脸的混合算法,试验结果和结论分别在第3和第4部分给出. 1 基于样本库学习和基于特征人脸的人脸图像放大方法
Simon Baker[7]提出的“Hallucination Face”方法基于局部结构特征识别,针对特定的图像类型.在吸收通用MAP超分辨率方法优点的同时,在针对Pr(Su)的处理上采用了不同的思路.在处理低分辨率人脸图像时,首先假定已有一个高分辨率的人脸库,将人脸库内的高分辨率图像和待处理的低分辨率图像用拉普拉斯金字塔表示,对于低分辨率图像中的任何一点,在对应的表示层的样本库中搜索邻域结构相似的点,显然只有在低分辨率情况下相似的结构才更有可能在高分辨率情况下相似,其各方向上的一阶导数和二阶导数也更有可能相似.假设这种相似的误差服从方差为σ2 Δ 的高斯分布,先验概率取如下分布:
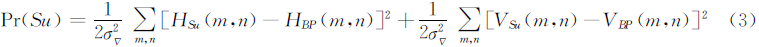
其中HSu(m,n) 和HBP(m,n)分别为在点(m,n)处高分辨率图像Su和匹配点的水平方向一阶导数,VSu(m,n)和 VBP(m,n)分别为竖直方向上的一阶导数.当然还可以增加对应方向二阶导数的对应项,但由于在二阶导数中通常会包含更多一些噪声,因此很多情况下只考虑一阶导数.
Gunturk[10]根据PCA分析,利用预先给定的人脸样本库来构造一组人脸图像空间的基,也称为特征脸(注意,这个正交向量的数量小于人脸的像素个数,不然就是整个空间的基,就不存在误差的问题).

与高分辨率人脸样本库对应的低分辨率样本库同样经过PCA分析得到一组低分辨率人脸图像空间的特征脸Ψ:

任何一幅人脸图像可以表示为特征脸的线性组合:

其中α是线性组合系数,eX是重构误差.
将高分辨率图像X和低分辨率观测图像Y进行以上的表示:

根据X、Y间的关系:

得到:

由于特征脸与重构误差正交,有ΨTeY=0,ΨTΨ =I,从(10)可以得到:
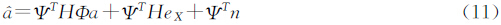
这个表达式与时域中的降晰过程相对应,是降晰过程在特征脸空间的表达式.(11)给出了未知的真实特征向量a与观测到的不精确的特征向量α间的关系.求解α的问题转化成MAP估计问题:

Pr(a)是a的先验知识,一般假定是高斯分布.
作者将空间域图像超分辨率问题转化到特征脸空间的超分辨率问题,将人脸图像作为整体来处理,而不是像在空间域中将图像进行分块或逐像素处理. 2 基于样本库学习和特征脸的混合算法
人脸图像是独特的一类图像.一方面,无论是我们认识的人脸,还是不认识的人脸,我们都能立刻识别出人脸这一特征;另一方面,无论人脸图像发生尺度变化还是几何变形、透视变形、加入大量噪声、模糊退化等,我们仍然能够识别出.可以想象,在图像空间中,人脸图像空间必定是一个很小的子空间,所以我们可以迅速的将人脸子空间与图像空间中其它子空间分别出来.如何界定这一子空间的特征对于我们在超分辨率算法中缩小解空间将有非常大的指导意义.
人脸在一定意义下是一个相似的结构.从整体上看,都有五官及相似的布局.从局部来看,各器官如眉、眼、鼻、嘴等都有各自特殊的形态结构.
自然图像局部结构存在如下规律①:不同图像内存在大量的相似局部结构;局部结构的相似性在不同尺度上保持.人脸图像依然存在这种规律.本文经过进一步实验发现,不同人脸图像的局部结构相似性比自然图像局部结构相似性体现得更明显.图1是一幅人脸图像在一个图像库中的块搜索结果.
 |
图1 人脸在图像库中搜索结果 上一排是在人脸图像库中搜索,下一排是在自然图像库中搜索 其中从左到右为原图、2×2搜索结果、3×3搜索结果、4×4搜索结果、6×6搜索结果、8×8搜索结果 The face searching results from the image database The top are results from face database and the bottom from nature image database From left to right is the result with block size 2×2,3×3,4×4,6×6,8×8 |
可以看到在人脸图像空间中,小尺度(2×2,3×3)的结构特征类型有限,因此对任一张人脸图像,都可以用小尺度块搜索得到非常近似的结果,尽管图像库的规模不大.在4×4的尺度上,结构特征类型则更丰富,有限的人脸图像库能够得到近似的结果,而自然图像库的结果则差一些,随着尺度的进一步增加,人脸图像库显示出更大的优势.图2是任选50张人脸照片进行如上搜索的PSNR分布.
 |
图2 人脸在不同图像库中搜索结果PSNR分布 A、B、C分别是块尺寸为4、6、8的搜索结果 虚线是从人脸库中搜索,实线是从自然图像库中搜索 The searching results′PSNR from different database A,B and C are the searching results with block size by 4,6,8 pixels,respectively Solid line is the result from face database,and the dashed from nature database |
另一方面,根据文献[10]中的PCA方法,考虑一幅图像X.
定义 =ΦΦTX,这时 落在人脸子空间中,可以看作是X向人脸空间的投影.对本文来说,正是这种投影将图像中与人脸无关的部分进行了有效去除,保留了与人脸有关的部分,从而可以将解空间限制在人脸子空间的一个子集中.称这一过程为投影到人脸库,这是对人脸图像的全局约束.图3是一些投影到人脸库的实验结果.
 |
图3 投影到人脸库的结果 上一行是原图,下一行是对应的投影结果 The results of project to the face database The results of project to the face database Top line are original images,the bottom are project results |
结合上述分析,本文采用如下的人脸图像超分辨率思路:先利用人脸图像的多尺度局部特征相似性进行特征结构搜索,将搜索结果再投影到人脸库以得到最终超分辨率结果.局部特征搜索方法改进自Simon Baker的方法.在Baker[7]的方法中采用超分辨率的Bayes框架如下:

将 Pr(Su)用基于识别的先验知识来表示:
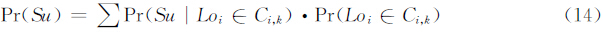
其中 Loi是低分辨率图像,Ci,k是对输入的Loi进行识别判决后得到的分类.在实际计算中,对训练图像库进行多级高斯金字塔和拉普拉斯金字塔分解,建立代表图像局部结构的结构向量(Parent Structure Vector),对低分辨率图像也进行同样的分解,只不过分解的级别要少.然后将每一个低分辨率图像的结构向量都在训练库的结构向量集中进行搜索,选取距离最小的结构向量,将其对应的图像的高频部分当作所搜索的低分辨率图像结构向量的高频部分.在数值计算的过程中,一般不用在一幅图像的全局搜索,只需在对应的坐标附近范围内搜索,这样可以节省时间,提高搜索速度,并且防止引入不必要的错误匹配.
在Baker的算法结果中,如果在训练库(图像分辨率96×128)中有与待处理的低分辨率图像(图像分辨率24×32)所对应的高分辨率图像,或属于同一人脸但与之稍有区别的图像,则可以取得完美的结果;如果待恢复图像与训练库中的所有图像都没有联系,则能取得可以接受的结果.当低分辨率图像分辨率降到12×12时,恢复效果进一步降低.因为此时随着图像分辨率的降低,能提供的指导特征搜索的图像边缘信息更少.Baker所利用的搜索原则可以归结为如下:在低频图像中相似的结构,其对应的高频图像更有可能相似,因此,Baker将最小距离的图像块直接作为匹配块.应用这种方法时,在训练库中存在对应的高频图像时,搜索到的最小距离值(为0)就是真实的解,能够精确的匹配;而在训练库中没有对应人脸的高频图像时,搜索到的最小距离值往往不一定是最相似的匹配块,因为从理想情况来看,不同人脸图像之间总是有差异的,出现距离为0的对应块的机率较小,而从实际数值计算来看,一个目标块总能找到一个或几个距离为0的匹配块,究其原因,有量化误差、噪声、也有训练图像库无法完全对齐归一、以及人脸图像总有轻微转动等因素,因而取得距离为0的块很有可能是错误的匹配块,真正的相似块反而被丢弃了.得不到较为理想的结果,只能得到一个可以接受的结果.
要改善这种情况,需要进行详细的分析.假设在搜索的过程中,针对低分辨率图像中的一点LR(x,y),在训练库的低分辨率图像中有n个最匹配的点(距离最小的前n个),对应的高分辨率图像块就是这点的n个有意义的超分辨率结果,也就是说,单独就一个点来看将解空间的规模从25616缩小到n个,这n个解满足如下约束:满足降采样约束,而且在人脸空间中,因此是有意义的结果.然而这样还不够,从整个图像来看,分辨率12×12的图像的解空间规模仍然有144n,这还是一个海量规模,如何在这个解空间中确定一个在一定准则下的最优解是本文要解决的首要问题.
根据前面对人脸图像局部相似性的分析,人脸大尺度的局部特征较为丰富,更容易区别不同的人脸,这也就意味着如果在大的尺度上相似的局部特征,其包含的相似的小尺度局部特征更有意义.如前所述,如果针对低分辨率图像的一点,有n个最有意义的超分辨率结果,在这n个结果中,更有意义的结果则显然是相似性更大的包含这个局部结构的更大尺度局部结构.这样就在一定程度上避免了单纯选择最相似的局部结构引起的问题,这种选择方法自然包含了图像块的边界约束.当然这种方法得到的结果是作为超分辨率结果的高频部分.低频部分可以直接用低分辨率图像,或者低分辨率图像的插值结果.本文利用如前所述的前n个最匹配图像块的均值作为图像的低频部分.
在通过局部特征相似性得到最优解后,将这个结果再投影到人脸库,以对图像的视觉效果进一步改善. 3 实验结果
实验图像库采用48×48的正面人脸库,手工对齐,其中左右内眼点坐标分别是(16,14),(30,14),鼻尖纵坐标27,嘴唇中间纵坐标39.将高分辨率图像版本进行高斯降采样,得到低分辨率图像库.在计算特征脸时,取对应前80个最大的特征值的特征向量.下面是这种搜索算法的结果.作为对比,根据[10]进行算法实现,列出相应的结果,见图4.
 |
图4 多尺度相似性约束后的搜索结果 从左到右分别是低分辨率图像、样条插值结果、本文算法搜索结果、原始高分辨率图像、[10]算法的结果 Searching result with multi-scale similarity constraint From left to right are low resolution images,spline method,proposed method,high resolution image and method[10] |
图4的图像是针对局部结构进行的搜索结果,将结果投影到人脸图像库中进行全局人脸相似性约束,得到的结果见图5.
 |
图5 多尺度相似性约束后的搜索结果 从左到右分别是低分辨率图像、样条插值结果、本文算法搜索结果、原始高分辨率图像、投影到人脸库中的结果 Searching result with multi-scale similarity constraint From left to right are low resolution images,spline method,proposed method,high resolution and project to face database |
本文利用人脸库以及人脸图像的相似性对超分辨率解空间进行约束:利用局部结构相似性将超分辨率解约束到人脸局部结构空间;将超分辨率解约束到人脸图像子空间,从而得到优化的超分辨率解.实验结果证明这种方法能够对极低分辨率人脸图像恢复大量的细节.
| [1] | Katsaggelos A K (Ed.). Digital Image Restoration[M]. Springer-Verlag. 1989. |
| [2] | Kang M G, Katsaggelos A K. Simultaneous multichannel image restoration and estimation of the regularization parameters[J]. IEEE Transactions on Image Processing, 1997, 6(5):774-778. |
| [3] | Schultz R R, Stevenson R L. A bayesian approach to image expansion for improved definition[J]. IEEE Transactions on Image Processing, 1994,3(3): 233-242. |
| [4] | Schultz R R, Stevenson R L. Extraction of high-resolution frames from video sequence[J]. IEEE Transactions on Image Processing, 1996, 5(6): 996-1011. |
| [5] | Sezan A M,Tekalp A. Superresolution video reconstruction with arbitary sampling lattices and nonzero aperture time[J]. IEEE Transactions on Image Processing, 1997, 6(8): 1064-1076. |
| [6] | Nguyen N, Milanfar P. A wavelet-based interpolation-restoration method for superresolution[J]. Circuits Systems and Signal Process, 2000, 19(40): 321-338. |
| [7] | Baker S, Kanade T. Limits on super-resolution and how to break them[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(9):1167-1183. |
| [8] | Strombeck J R. Superresolution with artificial neural networks.. http://www.dd.chalmers.se /-f96jost/superresolution/superresolution.htm. |
| [9] | Chang H, Yeung D Y, Xiong Y M.Super-resolution through neighbor embedding. 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’04)- Volume 1, 2004. 275-282. |
| [10] | Gunturk B K, Batur A U, Altunbasak Y, Hayes M H, Mersereau R M. Eigenface-domain super-resolution for face recognition[J]. IEEE Transactions on Image Processing, 2003,12(5), 597-606. |